
GitHub va a usar tu código para entrenar su IA. Si no haces nada, ya estás dentro.
Si ayer te llegó un email de GitHub con un tono muy amable hablándote de «mejoras en la asistencia de IA» y «prácticas habituales en la industria«, que sepas que lo que te están diciendo, en plata, es que a partir del 24 de abril van a usar todo lo que hagas con Copilot para entrenar los modelos de inteligencia artificial de Microsoft.

Tu código, tus conversaciones con Copilot, la estructura de tus proyectos, los nombres de tus archivos, tus comentarios en el código, todo. Y lo peor es que si no entras en los ajustes y lo desactivas tú, es posible que ya estés dentro. Esto es lo que se llama un modelo opt-out, es decir, que cuentan contigo salvo que digas expresamente que no.
Vamos a ver qué hay detrás de este cambio, qué implica para los que desarrollamos con WordPress y cómo protegerte si no te hace gracia.
¿Qué ha cambiado exactamente?
El 25 de marzo de 2026 GitHub publicó una actualización de su política de datos de interacción con Copilot junto con cambios en su política de privacidad y condiciones de servicio. El cambio principal es que los datos de interacción con GitHub Copilot de los usuarios de los planes Free, Pro y Pro+ se van a utilizar para entrenar y mejorar modelos de IA, salvo que el usuario se niegue.
La fecha límite es el 24 de abril de 2026. A partir de ese día, si no has tocado nada en tus ajustes, tus datos entran en el saco del entrenamiento.
Los usuarios de Copilot Business y Enterprise no se ven afectados, sus acuerdos prohíben usar esos datos para entrenamiento, los estudiantes y profesores con acceso gratuito a Copilot Pro tampoco, pero si pagas tu suscripción individual o usas el plan gratuito sí te afecta.
¿Qué datos recogen?
El alcance es bastante amplio. Cuando tienes la opción activada (que es como viene por defecto salvo una excepción que te cuento luego), GitHub puede recoger y usar para entrenamiento:
- Las sugerencias de código que aceptas o modificas.
- Lo que envías a Copilot, incluidos los fragmentos de código que ve el modelo.
- El contexto de código alrededor de tu cursor.
- Comentarios y documentación que escribas.
- Nombres de archivos, estructura de repositorios y patrones de navegación.
- Tus interacciones con las funciones de Copilot (chat, sugerencias inline, etc.).
- Tus valoraciones (pulgar arriba o abajo).
Es decir, prácticamente todo lo que haces mientras Copilot está activo.
Hay un detalle que pasa desapercibido y es importante, y es que GitHub distingue entre el código de tus repositorios privados «en reposo» (que dicen que no usan) y el código que Copilot procesa activamente cuando lo estás usando. Ese segundo caso sí entra en el entrenamiento.
Lo dicen ellos mismos en el anuncio, con las palabras exactas «at rest«, para dejar claro que mientras trabajas con Copilot en un repo privado, ese código sí puede acabar en el dataset.
¿Con quién comparten tus datos?
GitHub dice que estos datos se comparten con sus «afiliados», que en la práctica significa Microsoft y sus filiales. Personal de GitHub y Microsoft que trabaja en desarrollo de modelos de IA puede acceder a ellos, y también pueden contratar proveedores de servicios para ayudar con el entrenamiento, aunque bajo contrato.
Lo que dicen que no hacen es compartir estos datos con proveedores de modelos de IA de terceros ni venderlos. Eso sí, que los datos acaben en Microsoft, la empresa matriz que controla GitHub, y casualmente también accionista mayoritaria de OpenAI, no es exactamente que se queden «en casa».
Puedes consultar la FAQ oficial de GitHub con todas las preguntas frecuentes sobre este cambio.
El problema del opt-out en Europa
Desde el punto de vista legal, GitHub justifica el uso de datos de usuarios europeos apelando al «interés legítimo» como base legal bajo el RGPD. Es la misma estrategia que han usado Meta con los datos de Instagram y Facebook, y LinkedIn con los datos de sus usuarios para entrenar sus modelos.
El Comité Europeo de Protección de Datos (EDPB) reconoció en su dictamen de diciembre de 2024 que el interés legítimo puede servir como base para entrenar modelos de IA, pero con condiciones estrictas, vamos, que hay que demostrar que es necesario, hacer un análisis de proporcionalidad y tener en cuenta las «expectativas razonables» de los usuarios. Ofrecer un mecanismo de opt-out incondicional cuenta como medida positiva, y GitHub lo ofrece.
Pero la cosa no está tan clara como parece.
La autoridad italiana de protección de datos multó a OpenAI con 15 millones de euros en diciembre de 2024 por fallos en la evaluación del interés legítimo y en la transparencia al entrenar ChatGPT. Y NOYB, la organización de Max Schrems, ha presentado denuncias contra Meta en 11 países de la UE y contra X en 9 jurisdicciones por usar datos personales para entrenamiento de IA sin consentimiento explícito. Su posición es que el opt-out (aceptación implícita) no basta, debería ser opt-in (aceptación explícita).
Contra GitHub no hay denuncia todavía pero el patrón es idéntico al de Meta y X así que no sería raro que llegue.
Para los que vivimos en España la clave es que el RGPD exige que el consentimiento sea libre, específico, informado e inequívoco.
email con 30 días de aviso diciendo «si no haces nada, entendemos que aceptas» encaja mal con esa definición. Otra cosa es que GitHub pueda argumentar que no necesita consentimiento sino que se apoya en interés legítimo, pero esa base legal está siendo cuestionada en toda Europa para estos casos.
Lo que afecta a los desarrolladores WordPress
Aquí viene la parte que más nos toca. Si eres desarrollador WordPress y usas Copilot mientras trabajas en proyectos de clientes, piénsalo dos veces.
Cuando usas Copilot, el modelo tiene acceso al contexto de tu código, el archivo en el que estás, los archivos relacionados, los nombres de funciones, la estructura del proyecto. Si estás trabajando en el tema personalizado de un cliente, en un plugin con lógica de negocio específica o en cualquier código que no sea tuyo, fragmentos de ese trabajo pueden acabar en el dataset de entrenamiento de Microsoft.
Esto tiene implicaciones de confidencialidad serias.
Si tienes un contrato con tu cliente que incluye cláusulas de confidencialidad o de propiedad intelectual (y si no lo tienes, deberías), el hecho de que partes de su código puedan acabar alimentando un modelo de IA de una tercera empresa es, como mínimo, un problema contractual.
Y si tu cliente está en la UE y su código contiene datos personales (nombres en bases de datos, emails en configuraciones, etc.), también es un problema de RGPD.
La solución más directa es desactivar el entrenamiento en tus ajustes de Copilot. Puedes seguir usando Copilot con normalidad, simplemente tus datos no se envían para entrenar modelos.
Y para el proyecto WordPress en GitHub, ¿qué pasa?
El desarrollo de WordPress depende cada vez más de GitHub. La organización WordPress en GitHub tiene 191 repositorios públicos, siendo los más importantes Gutenberg (el editor de bloques, con más de 11.500 estrellas), wordpress-develop (el repo de desarrollo del core), WordPress Playground (WordPress en el navegador), Openverse (búsqueda de medios con licencia libre) y uno bastante goloso que se llama agent-skills, que proporciona conocimiento sobre WordPress a asistentes de código con IA.
El core de WordPress se sigue gestionando con Subversion como fuente canónica, y los repos de GitHub son espejos de solo lectura, pero Gutenberg se desarrolla de forma nativa en GitHub, con issues, pull requests y toda la infraestructura de CI/CD integrada. Incluso si quieres avisar de un fallo en el editor de WordPress en el Trac de WordPress te lo cierran y te mandan a GitHub.
Un matiz importante es que WordPress en GitHub no opera como una organización de pago con las protecciones de Copilot Business o Enterprise. Eso significa que la exención de entrenamiento para organizaciones de pago no se le aplican al proyecto.
Si un contribuidor a WordPress usa Copilot con su cuenta personal mientras trabaja en Gutenberg y no ha desactivado el entrenamiento, sus datos de interacción (que incluyen el contexto del código de Gutenberg) pueden acabar en el dataset.
Y lo más llamativo es que WordPress publicó en febrero de 2026 unas directrices de IA para contribuidores que dicen expresamente que se puede usar Copilot para contribuir al proyecto, siempre que se declare el uso, el resultado sea compatible con la GPL v2 y se revise todo, pero esas directrices se escribieron antes de este cambio de política. No dicen nada sobre el entrenamiento de datos, porque cuando se redactaron, este cambio no existía.
Tampoco hay ningún mecanismo a nivel de repositorio para impedir que los datos se usen. Un contribuidor del hilo de la FAQ de GitHub lo preguntó directamente, y GitHub confirmó que no hay opt-out por repositorio. Copilot funciona a nivel de cuenta individual, y la configuración del repositorio no puede anular la del usuario.
Comparado con otros proyectos de código abierto, la postura de WordPress es bastante permisiva con la IA. Gentoo Linux, por ejemplo, empezó a migrar de GitHub a Codeberg en febrero de 2026 precisamente por la presión de Copilot, y prohíbe directamente las contribuciones generadas con IA. La Software Freedom Conservancy abandonó GitHub en 2022 y lanzó una campaña de «Give Up GitHub» por los mismos motivos.
WordPress ha ido en la dirección contraria: repositiorio de agent-skills, archivos AGENTS.md en Gutenberg para dar contexto a los asistentes de código, Matt Mullenweg hablando con entusiasmo de que Claude Code y herramientas similares van a generar la mayoría de contribuciones en unos años. E
s una apuesta clara por la IA como herramienta de desarrollo, pero este nuevo cambio de GitHub plantea una pregunta que nadie ha respondido aún, y es que ¿debería el proyecto WordPress actualizar sus directrices para recomendar a sus contribuidores que desactiven el entrenamiento de datos cuando trabajan en repositorios del proyecto?
La cuestión de la GPL
WordPress usa la licencia GPL v2, y hay un debate legal abierto sobre si entrenar una IA con código GPL obliga a que el modelo resultante también sea GPL. A día de hoy ningún tribunal ha dictaminado eso. La GPL se escribió pensando en código fuente legible por humanos y en programas que «contienen» o «enlazan» código GPL, no en matrices de parámetros estadísticos que codifican patrones extraídos de millones de líneas de código.
Donde sí hay un problema real es en la salida. GitHub reconoce que aproximadamente un 1% de las sugerencias de Copilot pueden contener fragmentos de más de 150 caracteres que coinciden con el código de entrenamiento. Si Copilot reproduce código GPL tal cual, sin atribución ni aviso de licencia, eso es una violación práctica de la licencia aunque la teoría sobre el modelo en sí no esté resuelta.
El caso legal más relevante es Doe v. GitHub, la demanda colectiva presentada en noviembre de 2022 que acusa a Copilot de haberse entrenado con miles de millones de líneas de código sin respetar las licencias de código abierto. El tribunal desestimó las reclamaciones de copyright y DMCA, pero las de incumplimiento de contrato y violación de licencias open source siguen adelante. El caso está ahora en el noveno circuito de apelaciones y podría tener sentencia en 2026. Si sale a favor de los demandantes cambia las reglas para todo el sector.
Cómo desactivar el entrenamiento de la IA de Microsoft
El proceso es sencillo y no afecta al funcionamiento de Copilot. Sigues recibiendo sugerencias con normalidad, lo único que cambia es que tus datos dejan de alimentar los modelos.
- Ve a github.com/settings/copilot.
- Busca la sección de Privacy (Privacidad).
- Desactiva la opción que permite a GitHub usar tus datos para entrenamiento de modelos de IA.
- Guarda los cambios.
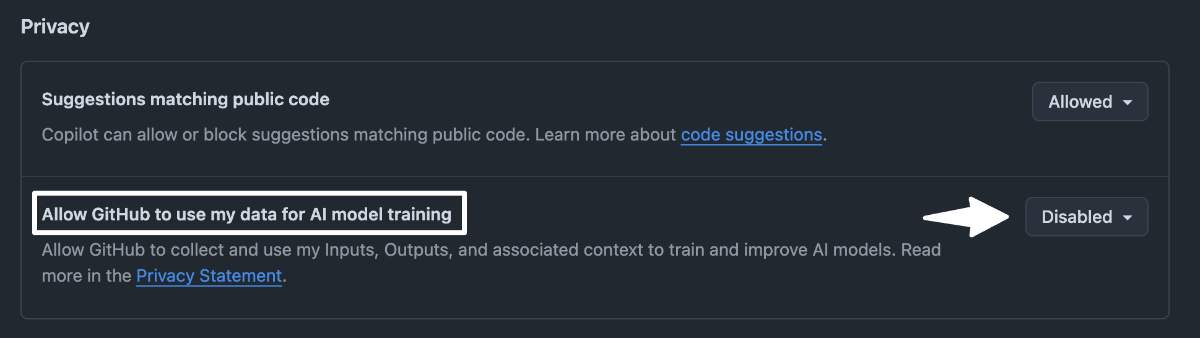
Si ya tenías desactivada la opción anterior de recopilación de datos para mejoras del producto, tu configuración se ha mantenido y no necesitas hacer nada.
Mi consejo es que lo desactives, especialmente si trabajas con código de clientes o contribuyes a proyectos de código abierto. No pierdes nada en la experiencia de uso de Copilot y te ahorras posibles problemas de confidencialidad y de cumplimiento normativo.
¿Y ahora qué?
Este cambio de GitHub no es un caso aislado ni de lejos, es la misma jugada que ya hemos visto con Meta, LinkedIn, X y Adobe de cambiar las condiciones por defecto, confiar en que la mayoría de usuarios no va a leerse el email ni cambiar nada, y usar esa inercia como base de datos de entrenamiento gratuita.
La diferencia con GitHub es que aquí no hablamos de fotos de vacaciones o publicaciones en redes sociales, hablamos de código. En GitHub subes código de trabajo, código de clientes, código de proyectos de código abierto con licencias específicas. El impacto potencial es más técnico, más contractual y más difícil de deshacer.
Mientras tanto, el caso Doe v. GitHub sigue su curso en apelación, las autoridades europeas de protección de datos siguen cuestionando los modelos de aceptación explícita (opt-out) para entrenamiento de IA, y la comunidad de código abierto sigue dividida entre los que abrazan la IA como herramienta de desarrollo y los que ven cómo su trabajo acaba alimentando modelos propietarios sin contrapartida.
Yo no estoy ni en un extremo ni en otro, sino en lo que creo que es lo más lógico, además de legítimo: abrazo la IA como herramienta, pero no admito que las empresas que venden la herramienta se apropien de mi contenido, creado con la herramienta o no.
Lo que sí puedes hacer ya mismo es entrar en tus ajustes de Copilot en GitHub y decidir por tu cuenta si quieres que tu código sirva para entrenar la IA de Microsoft. Eso no te lo puede decidir nadie más.
")


 de Google?")
¿Te gustó este artículo? ¡Ni te imaginas lo que te estás perdiendo en YouTube!
Muy buen artículo!
La verdad es que abre un debate bastante interesante, esto de la IA se está desmadrando y mucho y como siempre acabamos siendo el producto de todo.
No he entendido que querías decir con esto «Si ya tenías desactivada la opción anterior de recopilación de datos para mejoras del producto, tu configuración se ha mantenido y no necesitas hacer nada.» Yo la opción » Allow GitHub to use my data for AI model training » la tenía por defecto habilitada y la he tenido que deshabilitar y no veo ninguna sección más de privacidad a parte de esa.
MS nos está metiendo copilot hasta en la sopa para todo y a la fuerza …
No hay más secciones, la tendrías ya desactivada.
Lo de la IA, bueno, es genial, pero como toda nueva tecnología siempre hay abuso al principio